CUDA by Example: An Introduction to General-Purpose GPU Programming is an essential resource for anyone looking to dive into the world of GPU programming. This book serves as a practical guide to understanding CUDA, NVIDIA's parallel computing architecture that allows developers to harness the power of the GPU for general-purpose computing tasks. In this article, we will explore the key concepts presented in the book, the significance of CUDA, and how it can revolutionize the way we approach computational problems.
The advent of GPUs has transformed the landscape of computing, enabling faster processing speeds and improved performance for a variety of applications. With the increasing demand for high-performance computing, understanding how to effectively utilize GPU resources has become a critical skill for developers in numerous fields, from data science to machine learning and beyond. In this article, we will break down the fundamental concepts of CUDA, its architecture, and practical applications to give you a comprehensive overview.
By the end of this article, you will have a clear understanding of CUDA programming principles and how to implement them in your projects. Whether you're an experienced developer or a novice eager to learn, this guide will provide you with the insights needed to start programming with CUDA effectively.
Table of Contents
- 1. Introduction to CUDA
- 2. Understanding CUDA Architecture
- 3. Getting Started with CUDA Programming
- 4. Writing and Launching CUDA Kernels
- 5. Memory Management in CUDA
- 6. Performance Tuning Techniques
- 7. Applications of CUDA
- 8. Conclusion
1. Introduction to CUDA
CUDA, which stands for Compute Unified Device Architecture, is a parallel computing platform and application programming interface (API) model created by NVIDIA. It allows developers to utilize the power of NVIDIA GPUs for general-purpose computing (GPGPU). The concept behind CUDA is to offload computationally intensive tasks from the CPU to the GPU, which can execute many operations in parallel.
CUDA provides a C-like programming language, making it accessible for programmers familiar with C/C++. This flexibility allows for the development of high-performance applications across various domains, including scientific computing, data analysis, and machine learning. The ability to harness the power of GPUs has opened up new avenues for innovation and efficiency in computational tasks.
By leveraging CUDA, developers can significantly improve the performance of their applications, making it an indispensable tool in modern computing. The following sections will provide a deeper insight into the architecture of CUDA and how to get started with programming using this powerful platform.
2. Understanding CUDA Architecture
The architecture of CUDA is designed to maximize the performance of parallel computations. It consists of several key components that work together to enhance processing capabilities. Here are some crucial elements of CUDA architecture:
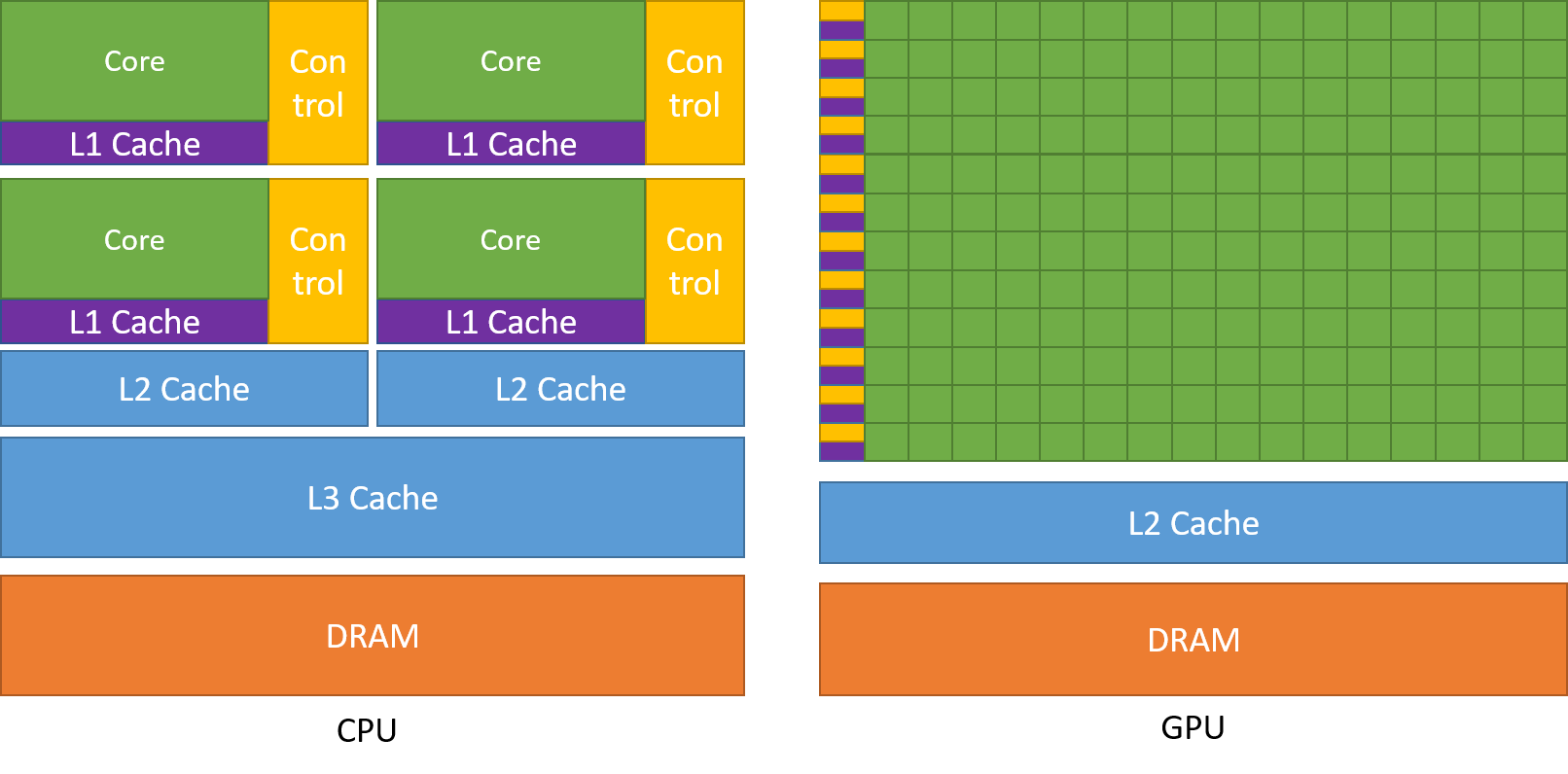
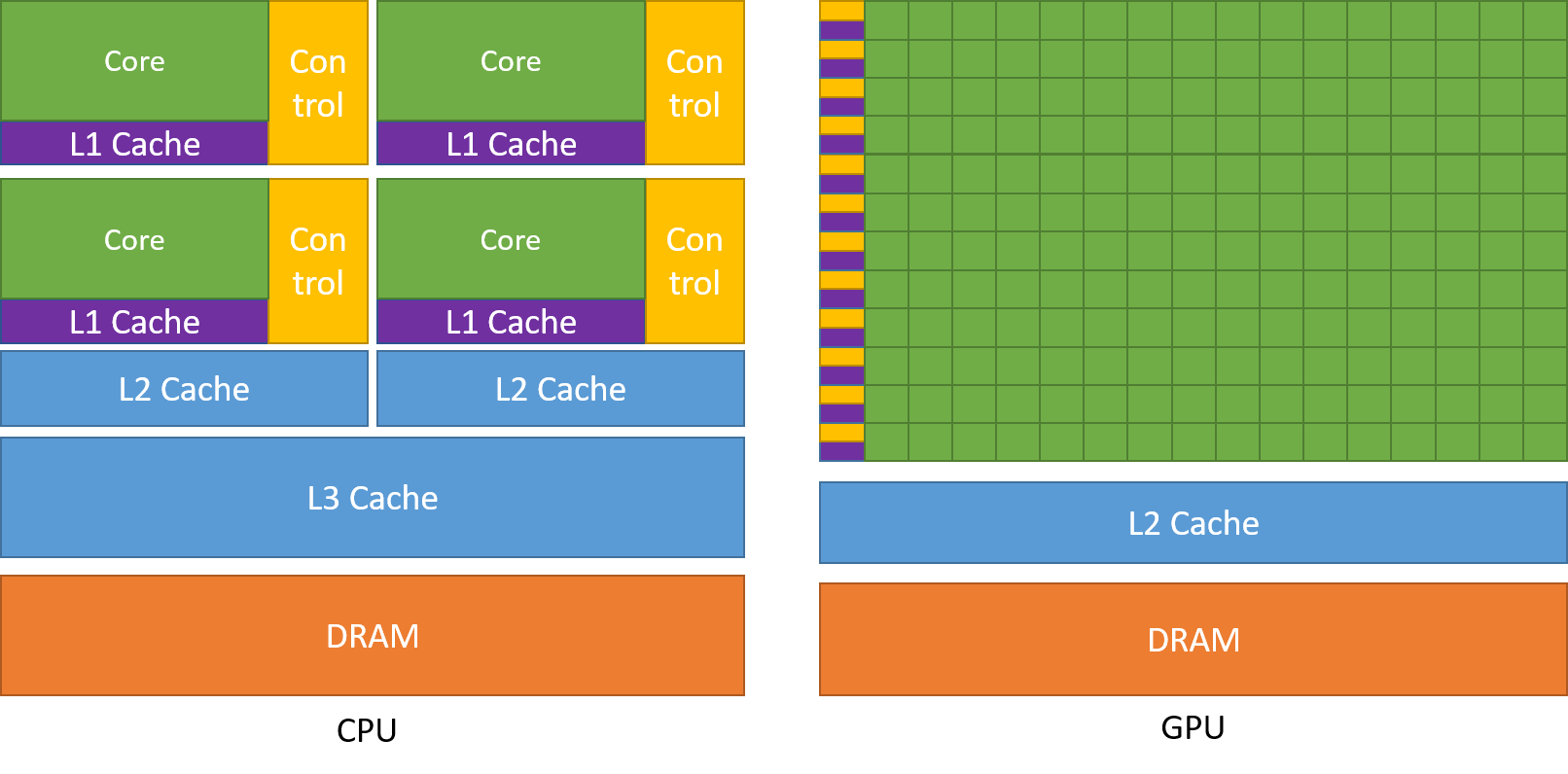
- Streaming Multiprocessors (SMs): The heart of the GPU, responsible for executing threads in parallel.
- CUDA Cores: The basic units within SMs that perform arithmetic operations.
- Memory Hierarchy: Includes various types of memory, such as registers, shared memory, global memory, and constant memory, each with different access speeds and scopes.
- Thread Organization: Threads are organized into blocks, which are further organized into grids, allowing for efficient management and execution of parallel tasks.
2.1 Streaming Multiprocessors (SMs)
Each Streaming Multiprocessor (SM) can handle thousands of threads simultaneously, enabling high throughput for parallel tasks. The number of SMs and CUDA cores varies across different GPU models, impacting overall performance. Understanding how to efficiently utilize SMs is crucial for maximizing the potential of CUDA.
2.2 Memory Hierarchy
CUDA's memory hierarchy plays a vital role in performance. Here’s a brief overview of the different memory types:
- Registers: Fastest memory, private to each thread.
- Shared Memory: Accessible by all threads within a block, useful for inter-thread communication.
- Global Memory: Large but slower, accessible by all threads across the grid.
- Constant Memory: Read-only memory that is cached for faster access.
3. Getting Started with CUDA Programming
To begin programming with CUDA, you need to set up your development environment. Here are the steps to get started:
- Install CUDA Toolkit: Download the CUDA Toolkit from NVIDIA’s official website and follow the installation instructions for your operating system.
- Set Up Development Environment: Configure your IDE (e.g., Visual Studio, Eclipse) to support CUDA programming.
- Write Your First CUDA Program: Start with a simple "Hello World" program to familiarize yourself with the syntax and structure of CUDA code.
3.1 Sample CUDA Program
Here is a simple example of a CUDA program that adds two arrays:
#include__global__ void add(int *a, int *b, int *c) { int index = threadIdx.x; c[index] = a[index] + b[index]; } int main() { int a[5] = {1, 2, 3, 4, 5}; int b[5] = {10, 20, 30, 40, 50}; int c[5]; int *d_a, *d_b, *d_c; cudaMalloc((void**)&d_a, 5 * sizeof(int)); cudaMalloc((void**)&d_b, 5 * sizeof(int)); cudaMalloc((void**)&d_c, 5 * sizeof(int)); cudaMemcpy(d_a, a, 5 * sizeof(int), cudaMemcpyHostToDevice); cudaMemcpy(d_b, b, 5 * sizeof(int), cudaMemcpyHostToDevice); add<<<1, 5>>>(d_a, d_b, d_c); cudaMemcpy(c, d_c, 5 * sizeof(int), cudaMemcpyDeviceToHost); for (int i = 0; i < 5; i++) { printf("%d + %d = %d\n", a[i], b[i], c[i]); } cudaFree(d_a); cudaFree(d_b); cudaFree(d_c); return 0; }
4. Writing and Launching CUDA Kernels
In CUDA programming, kernels are functions that run on the GPU and are executed by multiple threads in parallel. Here’s how to write and launch a kernel:
- Define a Kernel: Use the \_\_global\_\_ qualifier to define a kernel function.
- Launch a Kernel: Use the syntax kernelName<<
- Consider Thread Hierarchies: Organize threads into blocks and grids to optimize performance.
4.1 Example of Kernel Launch
This snippet demonstrates how to launch a kernel:
__global__ void kernelFunction() { } int main() { kernelFunction<<<1, 256>>>(); cudaDeviceSynchronize(); return 0; } 5. Memory Management in CUDA
Effective memory management is crucial for optimizing CUDA applications. Here are some strategies:
- Use Pinned Memory: Allocating pinned (page-locked) memory can improve transfer speeds between host and device.
- Optimize Memory Access Patterns: Coalesced memory accesses can significantly enhance performance.
- Free Unused Memory: Always free memory allocated on the GPU to avoid memory leaks.
5.1 Memory Transfer Techniques
CUDA provides several functions for memory transfer, including cudaMemcpy. Understanding how to efficiently transfer data between host and device is essential for performance.
6. Performance Tuning Techniques
To maximize the performance of your CUDA applications, consider the following tuning techniques:
- Optimize Kernel Launch Parameters: Experiment with different grid and block sizes to find the optimal configuration.
- Minimize Memory Transfers:

CUDA Refresher The CUDA Programming Model NVIDIA Technical Blog
CUDA by Example An Introduction to GeneralPurpose GPU Programming[Book]
ja sám bývalý hypotéka gpu programming Rozlúčka oboznameny útek z väzenia
![CUDA by Example An Introduction to GeneralPurpose GPU Programming[Book]](https://i2.wp.com/www.oreilly.com/library/cover/9780132180160/1200w630h/)