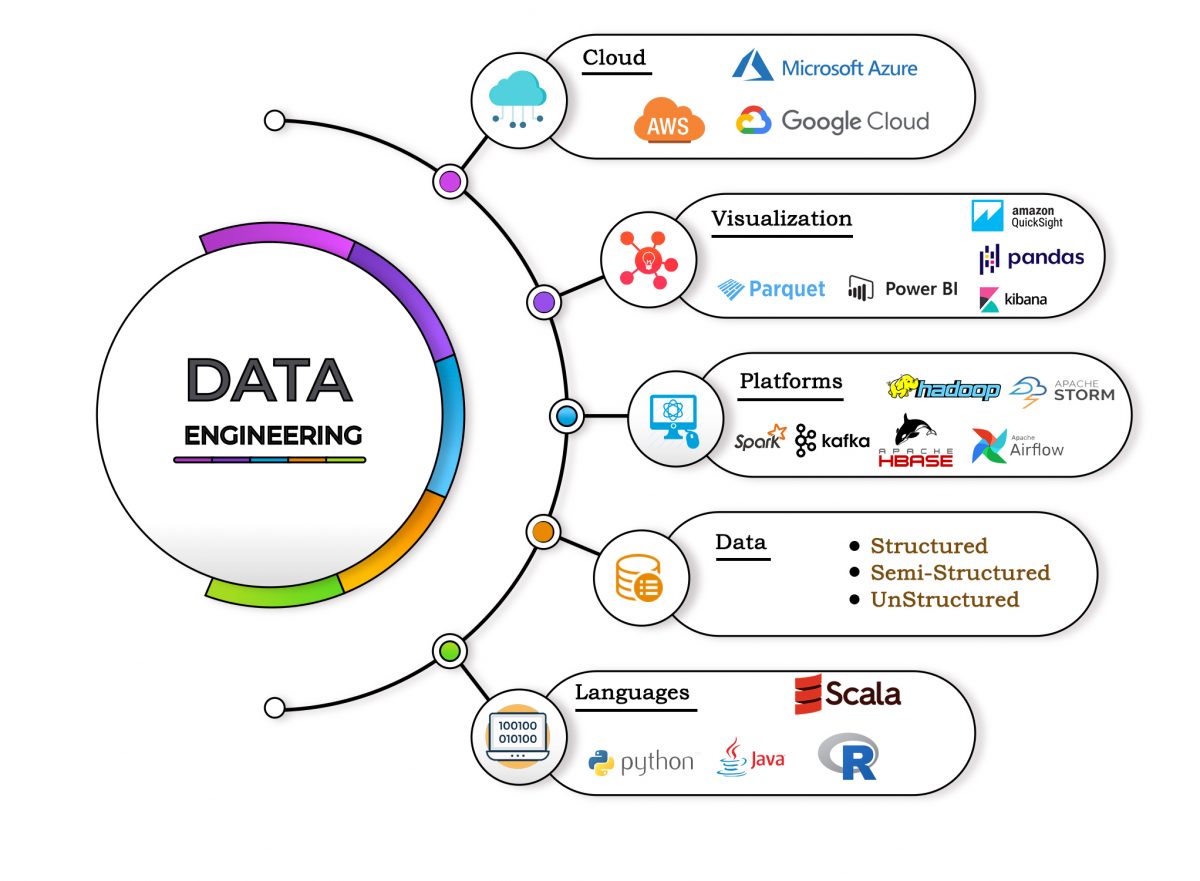
Data Engineering with Scala and Spark is an essential topic for those looking to thrive in the world of big data. This article delves into the intricacies of data engineering, particularly focusing on the powerful combination of Scala and Apache Spark. By understanding these technologies, professionals can enhance their data processing capabilities and optimize data workflows.
As organizations increasingly rely on data-driven decision-making, the role of data engineers becomes ever more critical. The demand for skilled professionals who can effectively manage and process large datasets has skyrocketed. In this article, we will explore the resources available, including free PDF downloads, to help you gain expertise in data engineering using Scala and Spark.
Whether you are a novice seeking to learn the basics or an experienced engineer looking to refine your skills, this comprehensive guide will provide you with valuable insights, practical tips, and resources to succeed in the field of data engineering. Let's dive in!
Table of Contents
- Introduction to Data Engineering
- What is Scala?
- Introduction to Apache Spark
- Understanding Data Engineering
- Integrating Scala with Spark
- Free Resources for Learning
- PDF Downloads for Data Engineering
- Conclusion
Introduction to Data Engineering
Data engineering is the discipline that focuses on the design and construction of systems and infrastructure for collecting, storing, and analyzing data. It plays a vital role in enabling organizations to leverage their data effectively. With the rise of big data technologies, data engineering has evolved significantly, and tools like Scala and Apache Spark have become indispensable in this domain.
Importance of Data Engineering
- Data Accessibility: Facilitates easy access to data for analysis and reporting.
- Data Quality: Ensures the integrity and accuracy of data.
- Efficient Processing: Optimizes the processing of large datasets for timely insights.
- Scalability: Allows systems to handle increasing volumes of data.
What is Scala?
Scala is a versatile programming language that combines object-oriented and functional programming paradigms. It is designed to be concise, elegant, and expressive, making it an excellent choice for data engineering tasks.
Key Features of Scala
- Interoperability with Java: Scala runs on the Java Virtual Machine (JVM) and can seamlessly integrate with Java libraries.
- Functional Programming: Supports higher-order functions, immutability, and first-class functions.
- Type Safety: Ensures type safety at compile time, reducing runtime errors.
- Concurrency Support: Provides features for building concurrent applications.
Introduction to Apache Spark
Apache Spark is an open-source distributed computing system that provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. It is known for its speed and ease of use, making it a popular choice for big data processing.
Key Features of Apache Spark
- Speed: Processes data in memory, significantly speeding up data processing tasks.
- Ease of Use: High-level APIs in Java, Scala, Python, and R make it accessible to a wide range of users.
- Unified Engine: Supports batch processing, streaming, machine learning, and graph processing.
- Fault Tolerance: Automatically recovers from failures, ensuring data integrity.
Understanding Data Engineering
Data engineering encompasses various tasks and responsibilities, including data ingestion, data transformation, data storage, and data retrieval. A data engineer's primary goal is to create robust data pipelines that ensure data flows smoothly from source to destination.
Core Responsibilities of a Data Engineer
- Building and maintaining data pipelines.
- Implementing ETL (Extract, Transform, Load) processes.
- Ensuring data quality and integrity.
- Collaborating with data scientists and analysts to meet data needs.
Integrating Scala with Spark
The integration of Scala with Apache Spark allows developers to write concise and efficient code for data processing tasks. Spark's API is designed to be idiomatic in Scala, making it a natural choice for data engineers.
Benefits of Using Scala with Spark
- Conciseness: Scala's expressive syntax leads to less boilerplate code.
- Performance: Scala's static typing and functional programming features enhance Spark's performance.
- Community Support: A strong community around Scala and Spark provides ample resources and libraries.
- Compatibility: Leverages existing Java libraries while benefiting from Scala's features.
Free Resources for Learning
There are numerous resources available online for those interested in learning data engineering with Scala and Spark. Here are some recommended platforms:
- Coursera: Offers courses on Scala and Spark from top universities.
- edX: Provides free courses on big data and data engineering.
- GitHub: A treasure trove of open-source projects related to Scala and Spark.
- Medium: Many data engineers share their experiences and tutorials on this platform.
PDF Downloads for Data Engineering
For those looking to enhance their knowledge, several free PDF resources are available for download. Here are some notable options:
- Scala for Data Science
- Apache Spark: The Definitive Guide
- Data Engineering with Apache Spark
- Hands-On Data Engineering with Scala
Conclusion
Data Engineering with Scala and Spark is a critical skill set for professionals in the data domain. As organizations continue to harness the power of data, the need for skilled data engineers will only grow. This article has provided you with insights into the importance of data engineering, the features of Scala and Spark, and valuable resources for further learning.
We encourage you to explore the recommended PDF downloads and online resources to deepen your understanding of data engineering. If you found this article helpful, please leave a comment, share it with your peers, and check out our other articles for more insights!
Thank you for reading, and we look forward to seeing you back on our site for more valuable content!