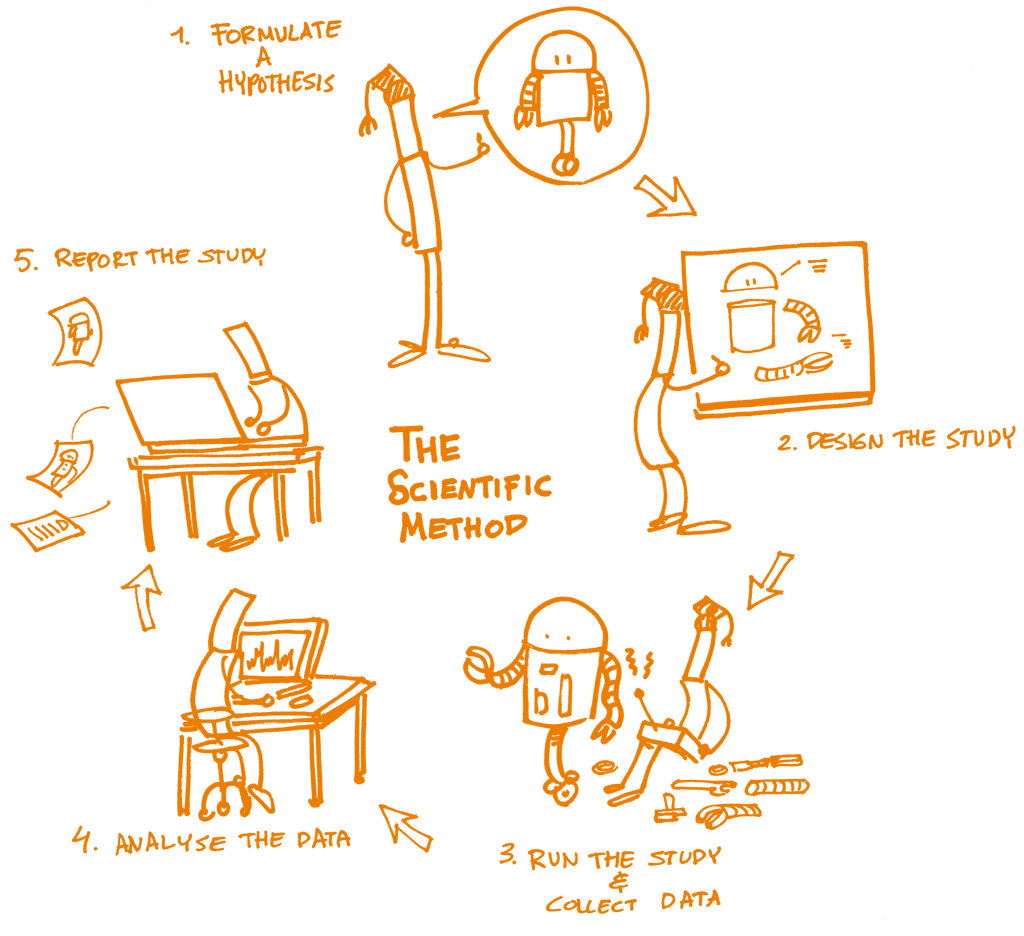
In the ever-evolving landscape of data science, reproducibility stands as a cornerstone of scientific integrity and innovation. The advent of tools like Pachyderm has revolutionized the way data scientists approach reproducibility, enabling them to create robust data pipelines that ensure consistent and reliable results. This article delves into the significance of reproducible data science, the role of Pachyderm, and how you can leverage its capabilities to enhance your data science projects.
Moreover, as data continues to grow in volume and complexity, the need for effective data management and reproducibility becomes increasingly critical. Pachyderm addresses these challenges head-on by providing a version-controlled data platform that integrates seamlessly with popular data processing frameworks. By the end of this article, you will have a comprehensive understanding of how to utilize Pachyderm for reproducible data science.
Whether you are a seasoned data scientist or just starting your journey, understanding reproducibility and the tools available is essential for successful data-driven projects. Let’s explore how Pachyderm can help you achieve reproducibility in your data science endeavors.
Table of Contents
- Introduction to Reproducible Data Science
- What is Pachyderm?
- Key Features of Pachyderm
- Setting Up Pachyderm for Your Project
- Building Reproducible Data Pipelines
- Best Practices for Reproducible Data Science
- Case Studies: Pachyderm in Action
- Conclusion
Introduction to Reproducible Data Science
Reproducible data science refers to the practice of documenting and sharing data analyses in a way that allows others to replicate the findings. This practice is essential for validating results and fostering collaboration in the scientific community. In a world where data is becoming increasingly complex, the ability to reproduce results is more important than ever.
One of the primary challenges in data science is ensuring that analyses can be replicated reliably. This challenge arises from various factors, including the complexity of data processing, the use of multiple tools, and the potential for human error. Reproducibility helps mitigate these issues by ensuring that all aspects of the analysis are transparent and accessible.
Pachyderm is a powerful tool that addresses these challenges by providing a version-controlled data platform. By leveraging Pachyderm, data scientists can create reproducible data pipelines that enable consistent results across different analyses. Let’s take a closer look at Pachyderm and its role in reproducible data science.
What is Pachyderm?
Pachyderm is an open-source data versioning and pipeline tool that enables data scientists to build reproducible data workflows. It combines data versioning with containerized data processing, allowing users to track changes in data and code simultaneously. This integration ensures that every step of the data analysis process is documented and can be reproduced reliably.
Key components of Pachyderm include:
- Data Versioning: Pachyderm automatically tracks changes to data and maintains a history of all versions.
- Data Pipelines: Users can define data processing workflows using Docker containers, ensuring that analyses are executed in a consistent environment.
- Reproducibility: Every analysis can be reproduced exactly as it was run, which is crucial for validation and peer review.
Key Features of Pachyderm
Pachyderm offers several key features that make it an invaluable tool for reproducible data science:
1. Version-Controlled Data
With Pachyderm, every dataset is versioned, allowing users to revert to previous versions or track changes over time. This feature is essential for maintaining the integrity of analyses and ensuring reproducibility.
2. Containerized Workflows
Pachyderm uses Docker containers to encapsulate data processing code, ensuring that analyses are executed in the same environment every time. This eliminates issues related to software dependencies and environment differences.
3. Scalability
Pachyderm is designed to handle large datasets and complex workflows, making it suitable for a wide range of data science projects. Its architecture allows for horizontal scaling, enabling users to process data efficiently.
4. Integration with Popular Tools
Pachyderm integrates seamlessly with popular data science tools such as Jupyter notebooks, TensorFlow, and Apache Spark, making it easy to incorporate into existing workflows.
Setting Up Pachyderm for Your Project
To get started with Pachyderm, follow these steps:
- Installation: Install Pachyderm on your local machine or cloud environment following the official documentation.
- Creating a Repository: Set up a new Pachyderm repository to store your datasets.
- Defining a Pipeline: Create a pipeline configuration file that specifies how your data will be processed.
- Running the Pipeline: Execute the pipeline to process your data and generate results.
Building Reproducible Data Pipelines
Building reproducible data pipelines with Pachyderm involves several key steps:
1. Data Ingestion
Ingest your data into Pachyderm by adding it to your repository. You can easily upload data from local files or external sources.
2. Pipeline Definition
Define your pipeline using a configuration file, specifying the data sources, processing steps, and output locations. Pachyderm uses a simple YAML format for pipeline definitions.
3. Execution and Monitoring
Run your pipeline and monitor its progress through the Pachyderm UI. You can view logs and track the status of each step in the pipeline.
4. Results and Versioning
Once the pipeline completes, you can access the results. Pachyderm automatically versions your output, allowing you to track changes over time.
Best Practices for Reproducible Data Science
To ensure the highest level of reproducibility in your data science projects, consider the following best practices:
- Document Your Work: Maintain thorough documentation of your analyses, including data sources, processing steps, and results.
- Use Version Control: Always version your data and code, ensuring that you can track changes and revert if necessary.
- Test Your Workflows: Regularly test your data pipelines to ensure they run as expected and produce consistent results.
- Share Your Code: Make your code accessible to others, allowing them to reproduce your analyses and contribute to your project.
Case Studies: Pachyderm in Action
Several organizations have successfully implemented Pachyderm for reproducible data science. Here are a few notable case studies:
1. Healthcare Analytics
A healthcare company utilized Pachyderm to analyze patient data, ensuring that their analyses could be reproduced across different teams. By leveraging Pachyderm’s version control and containerized workflows, they improved collaboration and reduced errors in their analyses.
2. Financial Modeling
A financial institution adopted Pachyderm to build reproducible models for risk assessment. With Pachyderm, they were able to track changes in their data and models, ensuring compliance with regulatory requirements.
3. Academic Research
Researchers in academia used Pachyderm to document their analyses for publication. By providing a reproducible workflow, they were able to enhance the credibility of their findings and facilitate peer review.
Conclusion
In conclusion, reproducible data science is essential for ensuring the integrity and reliability of data analyses. Pachyderm offers a powerful platform for building reproducible data pipelines, enabling data scientists to manage their data and workflows effectively. By adopting best practices and leveraging Pachyderm’s capabilities, you can enhance the reproducibility of your data science projects.
We encourage you to explore Pachyderm further and consider how it can benefit your data science endeavors. If you have any questions or insights, feel free to leave a comment below, and don’t forget to share this article with your colleagues and peers!
Thank you for reading, and we look forward to seeing you back on our site for more insights into data science