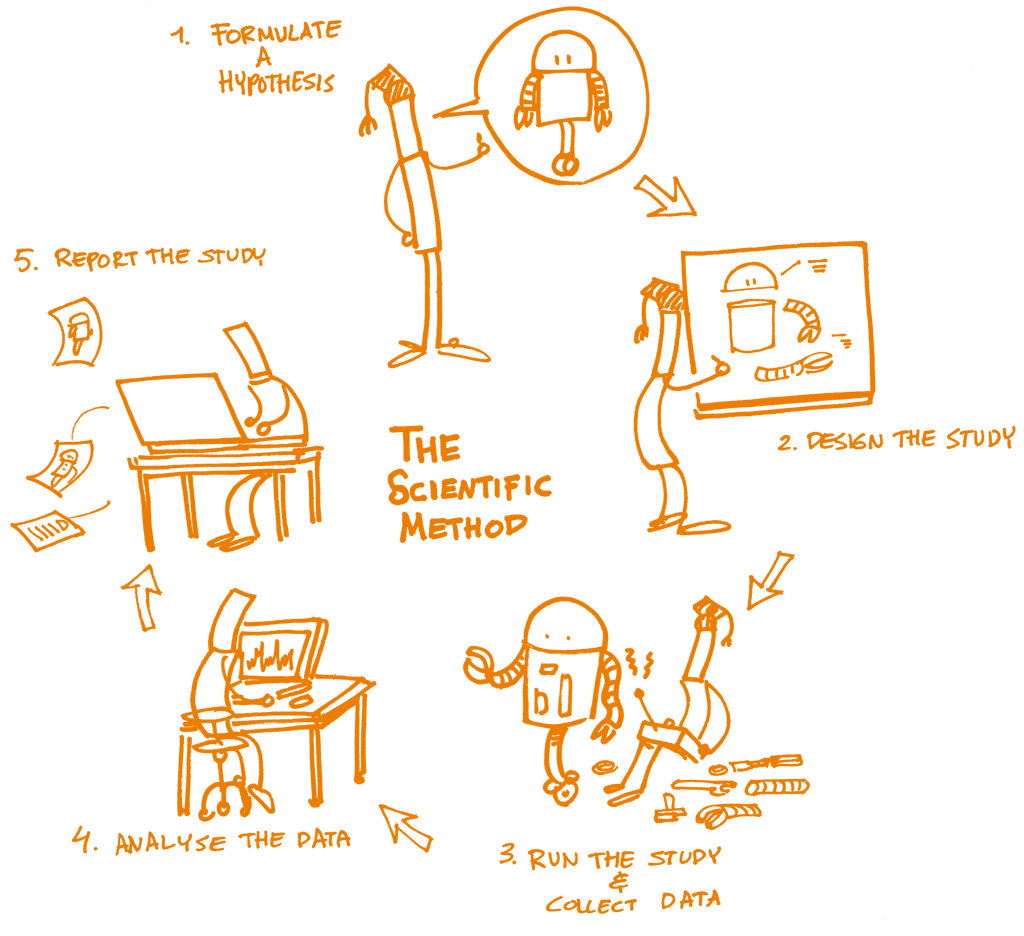
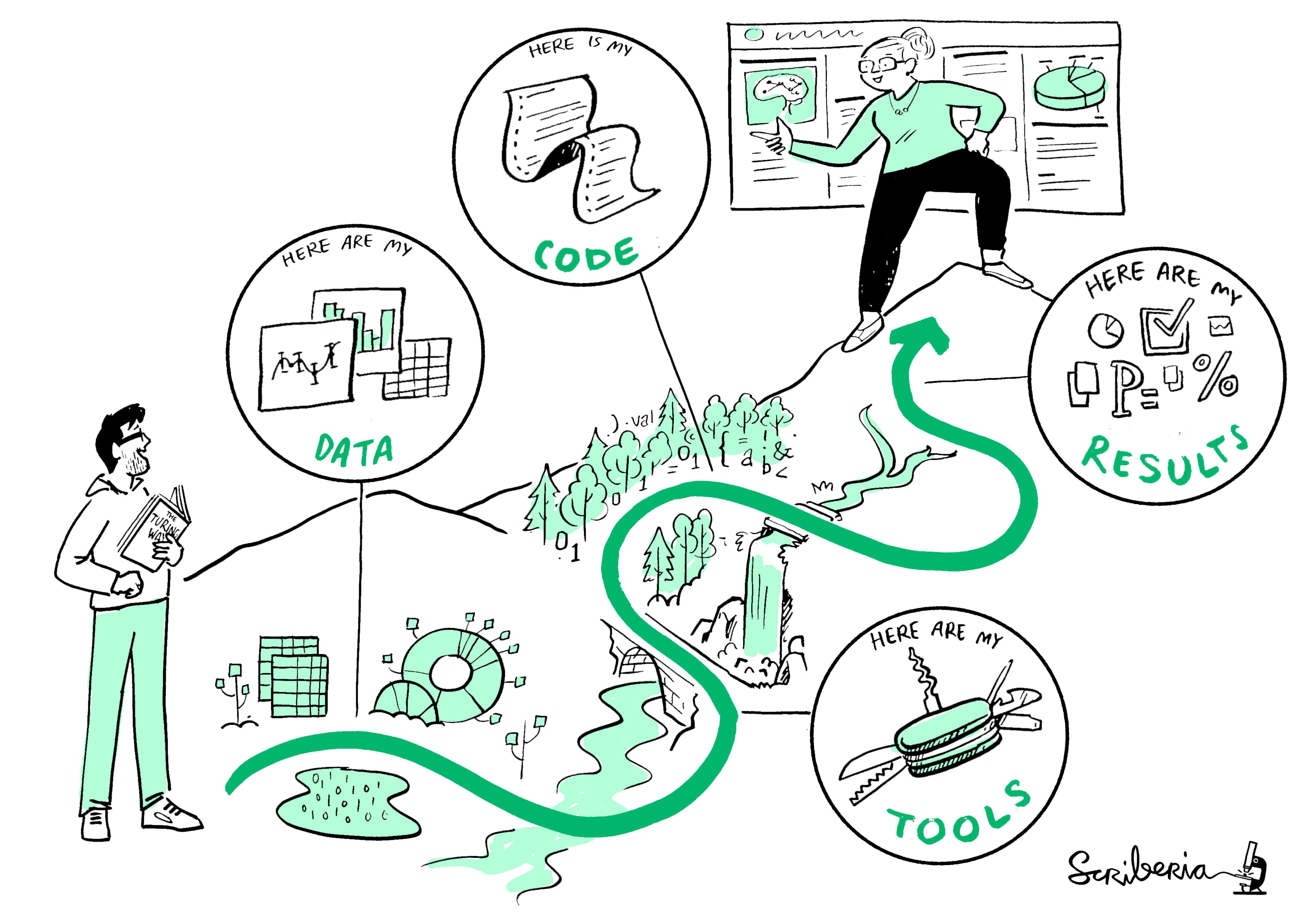
In the rapidly evolving field of data science, reproducibility has emerged as a cornerstone of scientific integrity and reliability. With the proliferation of data-driven decision-making across various industries, the need for reproducible results has never been more critical. This article delves into the concept of reproducible data science, focusing on the role of Pachyderm as a powerful tool in achieving this goal. We will explore the insights presented by Svetlana Karslioglu in her comprehensive PDF guide, which offers invaluable resources for practitioners at all levels.
Understanding the intricacies of reproducible data science is essential for researchers, data scientists, and organizations aiming to maintain credibility in their findings. The discussion will encompass the methodologies that promote reproducibility, the significance of versioning data and code, and how Pachyderm facilitates these processes. By the end of this article, readers will have a clearer understanding of how to implement reproducible practices in their data science workflows.
Furthermore, we will provide access to Svetlana Karslioglu's PDF guide, which serves as a practical resource for anyone looking to enhance their knowledge and skills in reproducible data science. Whether you are a beginner or an experienced data scientist, this article aims to equip you with the necessary tools and insights to excel in your projects.
Table of Contents
- What is Reproducible Data Science?
- Importance of Reproducibility in Data Science
- Introduction to Pachyderm
- Features of Pachyderm
- Svetlana Karslioglu and Her PDF Guide
- How Pachyderm Ensures Reproducibility
- Case Studies: Success Stories with Pachyderm
- Getting Started with Pachyderm
What is Reproducible Data Science?
Reproducible data science refers to the practice of ensuring that data analyses can be duplicated by others using the same methods and data. This concept is crucial for validating research findings and fostering trust in data-driven conclusions. Key elements of reproducibility include:
- Clear documentation of data sources and methodologies.
- Version control for both data and code.
- Utilization of standardized tools and environments.
Importance of Reproducibility in Data Science
Reproducibility is vital for several reasons:
- Scientific Integrity: Ensures that results can be verified and trusted.
- Collaboration: Facilitates teamwork by allowing multiple researchers to work on the same project seamlessly.
- Efficiency: Saves time and resources by preventing duplicated efforts and errors.
Introduction to Pachyderm
Pachyderm is an open-source data versioning and data lineage tool designed to facilitate reproducible data science workflows. It integrates seamlessly with popular data science tools and provides a robust framework for managing data and code versions. Key features include:
- Data versioning and lineage tracking.
- Integration with containerization technologies like Docker.
- Support for various data storage backends.
Features of Pachyderm
Data Versioning
Pachyderm allows users to version their data, ensuring that every change is tracked and can be reverted if necessary. This feature is imperative for maintaining the integrity of data analyses.
Data Lineage
The tool provides a clear lineage of data transformations, enabling users to trace how data has evolved over time. This is particularly useful for auditing and debugging purposes.
Svetlana Karslioglu and Her PDF Guide
Svetlana Karslioglu is a prominent figure in the field of data science, known for her expertise in reproducible research practices. Her PDF guide offers practical insights and techniques for implementing reproducibility in data science projects. The guide covers topics such as:
- Best practices for data documentation.
- Using Pachyderm for version control.
- Strategies for effective collaboration.
How Pachyderm Ensures Reproducibility
Pachyderm enhances reproducibility by allowing users to:
- Maintain a comprehensive history of changes through version control.
- Reproduce analyses by executing the same code and using the same data versions.
- Share workflows with collaborators easily.
Case Studies: Success Stories with Pachyderm
Several organizations have successfully implemented Pachyderm to achieve reproducible data science outcomes. Notable examples include:
- Healthcare Analytics: A healthcare provider used Pachyderm to track patient data analyses, ensuring compliance with regulations.
- Financial Services: A financial institution adopted Pachyderm for risk assessment models, enhancing transparency and reliability.
Getting Started with Pachyderm
To begin using Pachyderm for reproducible data science, follow these steps:
- Install Pachyderm by following the official documentation.
- Create a repository for your data.
- Begin versioning your data and code as you conduct analyses.
Conclusion
In conclusion, reproducible data science is an essential practice for ensuring the reliability and validity of data analyses. By utilizing tools like Pachyderm, practitioners can enhance their workflows and promote transparency in their findings. We encourage readers to explore Svetlana Karslioglu's PDF guide for further insights and to consider adopting reproducible practices in their own projects.
We invite you to leave your comments, share this article, or explore more resources on our site to deepen your understanding of reproducible data science.
Penutup
Thank you for taking the time to read this article. We hope you found it informative and engaging. Stay tuned for more articles that will help you navigate the exciting world of data science!