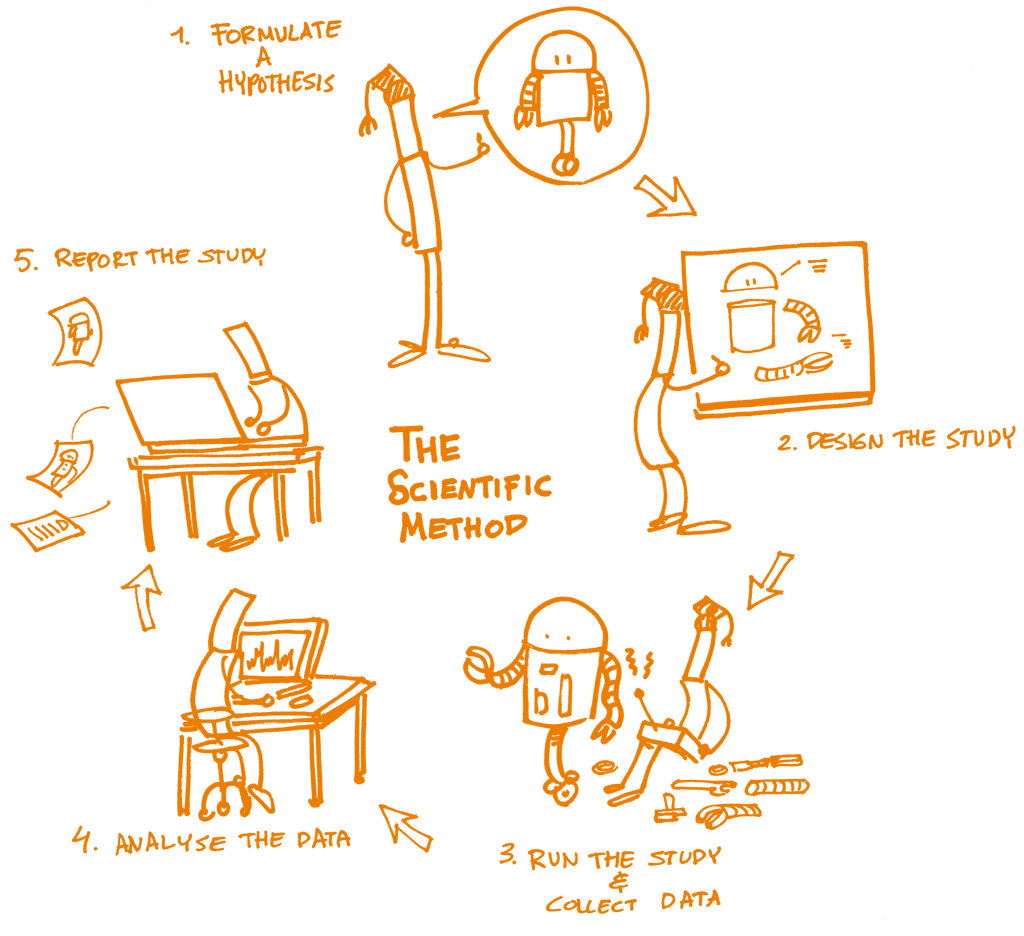
In the realm of data science, reproducibility is crucial for ensuring that analyses can be repeated and verified. This article dives deep into the topic of reproducible data science using Pachyderm, a powerful tool that streamlines data management and workflow orchestration. As data science continues to evolve, understanding how to leverage such tools effectively becomes paramount for both novice and experienced practitioners.
This guide aims to provide a comprehensive overview of Pachyderm and its capabilities in creating reproducible data science workflows. Whether you are a data scientist looking to enhance your skills or a project manager seeking to implement best practices in your team, this article will equip you with the knowledge you need. In addition, we will be offering a free PDF guide that encapsulates the key concepts discussed, making it easy for you to reference and share.
By the end of this article, you’ll not only understand the importance of reproducibility in data science but also how Pachyderm can help you achieve it. We will explore its features, benefits, and how to get started with this powerful platform. So, let’s embark on this journey to mastering reproducible data science!
Table of Contents
- What is Pachyderm?
- The Importance of Reproducibility in Data Science
- Key Features of Pachyderm
- Setting Up Pachyderm for Your Projects
- Using Pachyderm for Reproducible Data Science
- Case Studies: Success Stories with Pachyderm
- Download Your Free PDF Guide
- Conclusion
What is Pachyderm?
Pachyderm is an open-source data versioning and data pipeline tool that offers a unique approach to managing data workflows in data science projects. Unlike traditional data management systems, Pachyderm treats data as a first-class citizen, allowing users to track changes, perform data lineage, and ensure reproducibility effortlessly. This is particularly important in an era where data is constantly evolving and the need to reproduce results is critical.
Key Components of Pachyderm
- Data Versioning: Pachyderm provides built-in version control for your data, similar to Git for code.
- Data Lineage: Users can visualize and track the origins and transformations of their datasets.
- Pipeline Management: Create and manage complex data pipelines with ease, integrating various data processing tools and languages.
The Importance of Reproducibility in Data Science
Reproducibility is a cornerstone of scientific research, and it holds the same significance in data science. When analyses can be reproduced, it enhances trust in the findings and allows others to validate results. Here are some key reasons why reproducibility is essential:
- Validation of Results: Reproducible results can be independently verified, increasing confidence in the findings.
- Collaboration: Teams can work together more effectively when they can reproduce each other's work.
- Learning and Development: New data scientists can learn from existing analyses when they can replicate them.
Key Features of Pachyderm
Pachyderm offers several features that make it an invaluable tool for data scientists aiming for reproducibility:
- Data Provenance: Track the history of data changes and transformations.
- Automated Pipelines: Trigger data processing pipelines automatically based on data changes.
- Integration with Popular Tools: Seamlessly work with tools like Jupyter Notebooks, TensorFlow, and others.
Benefits of Using Pachyderm
- Enhanced Collaboration: Facilitate teamwork by ensuring everyone has the same data versions.
- Increased Efficiency: Automate repetitive tasks, allowing data scientists to focus on analysis.
- Scalability: Handle large datasets and complex workflows without compromising performance.
Setting Up Pachyderm for Your Projects
Getting started with Pachyderm is straightforward. Follow these steps to set it up for your data science projects:
- Install Pachyderm: Follow the installation guide on the official Pachyderm website.
- Create a Repository: Set up a new repository to manage your datasets.
- Define Your Pipelines: Create pipelines that specify how data should be processed.
Best Practices for Configuration
- Ensure that your data is well-organized within your repositories.
- Document your pipeline configurations to facilitate collaboration.
- Regularly update and version your datasets to maintain integrity.
Using Pachyderm for Reproducible Data Science
To leverage Pachyderm effectively, here are some key steps to follow:
- Data Ingestion: Import your datasets into Pachyderm repositories.
- Build Your Pipelines: Write the necessary code to process your data according to your analysis needs.
- Run and Monitor: Execute your pipelines and monitor their performance through the Pachyderm dashboard.
Potential Challenges and Solutions
- Learning Curve: Familiarize yourself with Pachyderm's documentation and community forums for support.
- Data Size Management: Utilize Pachyderm's versioning features to manage large datasets effectively.
Case Studies: Success Stories with Pachyderm
Several organizations have successfully implemented Pachyderm to enhance their data science workflows:
- Research Institutions: Many universities have adopted Pachyderm to manage research data and ensure reproducibility.
- Tech Companies: Leading tech companies utilize Pachyderm for data product development and analytics.
Download Your Free PDF Guide
We have created a comprehensive PDF guide that summarizes the key points discussed in this article. This guide is designed to help you quickly reference important information about reproducible data science with Pachyderm. Click the link below to download your free copy:
Conclusion
In conclusion, reproducible data science is not just a desirable practice; it is essential for maintaining the integrity and reliability of data analyses. Pachyderm provides a robust framework for achieving this reproducibility through its innovative features and capabilities. By adopting Pachyderm, you can streamline your data workflows and ensure that your analyses are verifiable and collaborative.
We encourage you to leave a comment below, share this article with your colleagues, or check out our other resources for further reading on data science best practices.
Penutup
Thank you for exploring the world of reproducible data science with Pachyderm. We hope to see you back on our site for more insightful articles and resources that will enhance your data science journey!