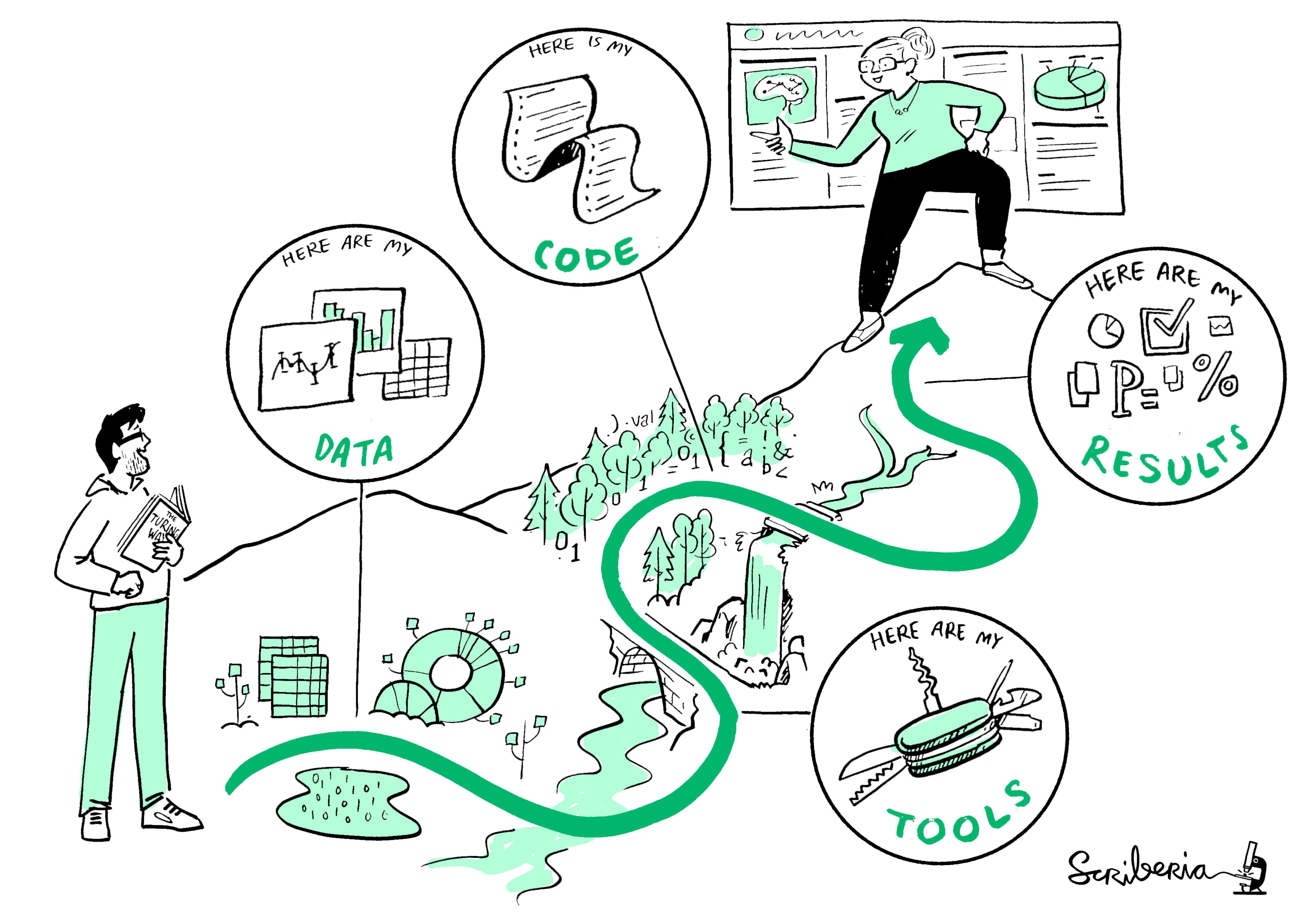
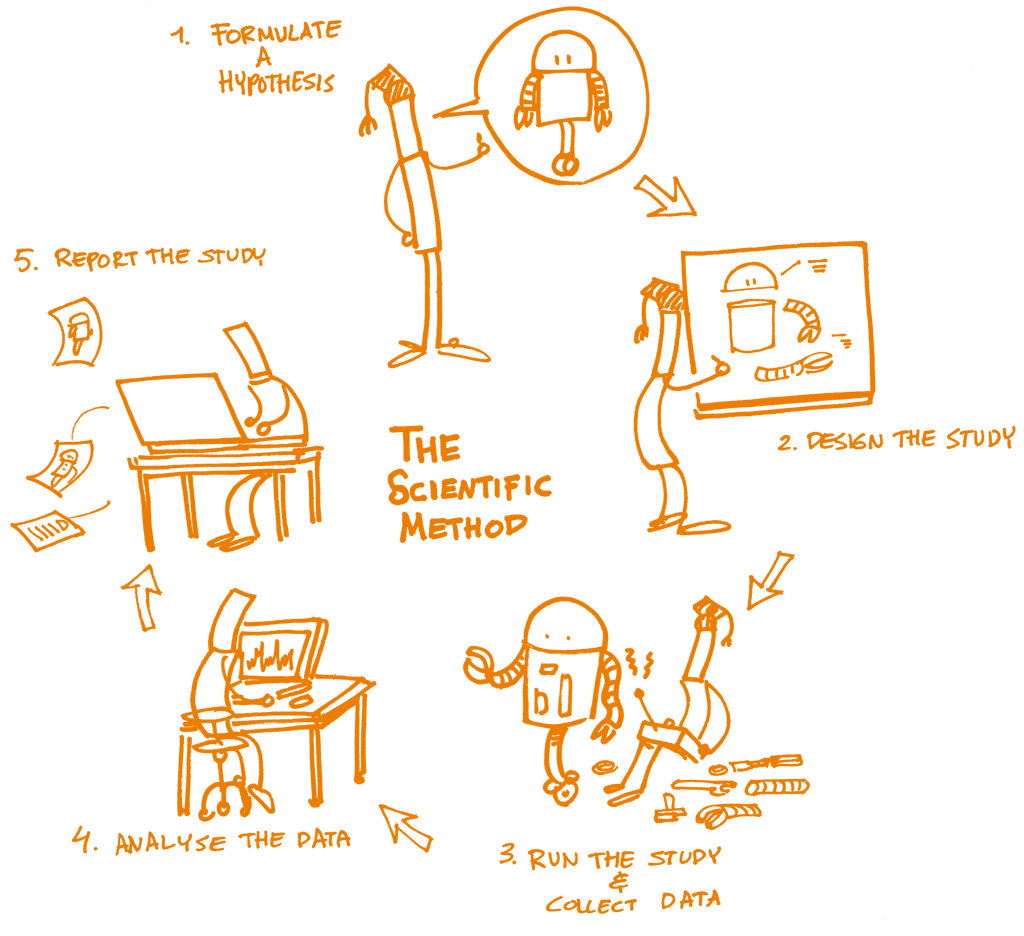
In the ever-evolving landscape of data science, reproducibility has emerged as a critical aspect for researchers and practitioners alike. Reproducible Data Science with Pachyderm not only streamlines the data workflow but also enhances collaboration and transparency in data projects. This article will explore the functionalities of Pachyderm, its significance in ensuring reproducibility, and how you can access valuable resources, including a downloadable PDF guide.
With the growing emphasis on reproducibility in data science, tools like Pachyderm have gained traction among data scientists. Pachyderm offers a robust platform that integrates version control with data pipelines, allowing teams to track changes, share datasets, and reproduce analyses effortlessly. In this article, we will delve into the features of Pachyderm, best practices for reproducible data science, and provide insights on how to download the comprehensive PDF guide.
Whether you are a seasoned data scientist or just starting your journey, understanding the principles of reproducibility and leveraging the right tools can significantly impact your work. This article aims to equip you with the knowledge and resources to enhance your data science projects through Pachyderm.
Table of Contents
- Understanding Reproducibility in Data Science
- What is Pachyderm?
- Key Features of Pachyderm
- Setting Up Pachyderm
- Best Practices for Reproducible Data Science
- PDF Guide Download
- Case Studies and Real-World Application
- Conclusion
Understanding Reproducibility in Data Science
Reproducibility is the ability to obtain the same results using the same data and methodologies. In data science, this means that others should be able to replicate your findings, leading to greater trust and credibility in your work. The importance of reproducibility cannot be overstated, especially in fields where data-driven decisions can have significant consequences.
Why is Reproducibility Important?
- Enhances credibility and trust in research outcomes.
- Facilitates collaboration among data scientists and teams.
- Encourages transparency and accountability in data handling.
- Aids in troubleshooting and debugging analyses.
What is Pachyderm?
Pachyderm is an open-source data versioning and pipeline management tool designed to facilitate reproducible data science. It provides a framework for building data pipelines while keeping track of versions of data and code, ensuring that analyses can be replicated with ease.
Core Components of Pachyderm
- Data Versioning: Similar to Git for code, Pachyderm allows users to version datasets, making it easy to track changes over time.
- Data Pipelines: Users can create pipelines to automate data processing workflows, ensuring consistent and reproducible results.
- Containerization: Pachyderm leverages Docker containers to encapsulate dependencies, ensuring that analyses run in consistent environments.
Key Features of Pachyderm
Pachyderm boasts several key features that make it an invaluable tool for data scientists seeking reproducibility.
- Integration with Popular Data Tools: Pachyderm seamlessly integrates with tools like Jupyter, TensorFlow, and Apache Spark, enhancing its usability across various data science projects.
- Scalability: Designed to handle large datasets, Pachyderm scales effortlessly, making it suitable for both small and large projects.
- Collaborative Workflows: Teams can collaborate effectively, as Pachyderm allows multiple users to work on the same project without conflicts.
- Data Provenance: Pachyderm tracks the lineage of data, ensuring that users can trace back to the original sources and changes made over time.
Setting Up Pachyderm
Getting started with Pachyderm is relatively straightforward. Here are the essential steps for setting up Pachyderm in your environment:
- Install Docker on your machine.
- Follow the official Pachyderm installation guide to set up Pachyderm on your local machine or cluster.
- Familiarize yourself with the command-line interface (CLI) for interacting with Pachyderm.
- Create your first data repository and pipeline using the provided tutorials.
Best Practices for Reproducible Data Science
To maximize the benefits of Pachyderm and ensure your data science projects are reproducible, consider the following best practices:
- Document your data sources and methodologies clearly.
- Use version control for both data and code.
- Adopt modular coding practices to enhance reusability.
- Encapsulate your environment using Docker to minimize dependency issues.
PDF Guide Download
For those looking for a comprehensive resource on reproducible data science with Pachyderm, a detailed PDF guide is available for download. This guide includes:
- In-depth explanations of Pachyderm features.
- Step-by-step tutorials for setting up and using Pachyderm.
- Case studies demonstrating real-world applications.
You can download the PDF guide here.
Case Studies and Real-World Application
Many organizations have successfully implemented Pachyderm to enhance their data science workflows. Here are a couple of notable case studies:
Case Study 1: E-commerce Analytics
An e-commerce company utilized Pachyderm to streamline their customer analytics pipeline. By implementing data versioning and reproducible workflows, they were able to make data-driven marketing decisions that increased their conversion rates by 15%.
Case Study 2: Healthcare Research
A healthcare research team employed Pachyderm to manage their clinical trial data. The ability to reproduce analyses ensured that their findings were credible and could be easily reviewed by regulatory bodies.
Conclusion
Reproducible data science is a cornerstone of credible research and effective data-driven decision-making. With tools like Pachyderm, data scientists can ensure their workflows are transparent, collaborative, and easily replicable. By following best practices and utilizing the resources available, you can enhance your data science projects significantly.
We encourage you to explore the PDF guide on reproducible data science with Pachyderm, and start implementing these practices in your own work. If you found this article helpful, feel free to leave a comment, share it with your colleagues, or check out our other articles for more insights.
Thank you for reading, and we look forward to seeing you back on our site for more valuable content!